Over the course of this last semester, I believe I have gained a respectable amount of exposure to techniques and industry standards in the field of software engineering. Having taken Object Oriented Programming last (Spring) semester and Software Engineering this Fall with Dr. Downing, I have learned invaluable information that will no doubt stay with me for years to come.
I believe one of the most valuable things I have learned is how to work with a group. I currently work at ARM, but I am mostly a one man show. I work with a collection of engineers that tell me what they want, and I do it. In a way, the computer engineers are my consumer, and I am constantly going back and forth with them, creating new features and determining the next feature to implement with the highest priority. Another is testing. Dr. Downing stresses and stresses test driven development. You test first, you reap the rewards. You get things done correctly. Your code changes work predictably. If you do not test first, you develop software that is half-baked. It is not guaranteed to work. You have no real way to demonstrate that your code works, and no real way to test your consistently test your changes against the established behavior of the system, and make sure it complies.
I encourage all comp-sci students at UT Austin to take Dr. Downing's class. The information he gives is truly invaluable, and he always presents it in a way that prevent you from simply slipping by. His classes are truly in-your-face and get down to the nitty-gritty of various C.S. languages. As far as I am concerned, there is no better person to learn C++ or python from. He will not only teach you the language, but he will also tell you how badly they suck. Java sucks. C++ sucks. Haskell sucks. Of course, they all have their respective benefits, but he doesn't simply begin a love story with a language when you take a class from him. He will tell you what makes the language beautiful, but will not forget to tell you what truly doesn't make sense.
All in all, I might not make extravagant grades in Dr. Downing's classes like I do in others, but I learn an incredible amount. Dr. Downing, you will truly be missed. Peace.
Sunday, December 9, 2012
Friday, December 7, 2012
Paper Blog: Behavior Driven Development
Edit: the original paper by Dan North can be found here
Over the course of this last semester, I have learned a lot about tools and best practices for software engineering and development. This includes topics such as Agile Development, TDD (Test Driven Development), Extreme Programming, and efficient use of pair programming. Most of these development practices overlap and can be used in conjunction with one another. The problem is that to someone new to these things, it all can seem a bit overwhelming.
Dan North saw these issues and created something called behavior-driven development (BDD), as described on his blog here. Over the years Dan has been teaching and running many courses over subjects involving accelerated agile and behavior-driven development. He even has a few conferences he will be teaching at over the next few months over accelerated agile development! In his words, "[BDD]... is designed to make them [agile practices] more accessible and effective for teams new to agile software delivery".
In earlier years, when Dan was trying to fine tune his agile development and TDD skills, a series of "Aha!" moments are what drove him to create BDD. First, test method names should be sentences. Even the method names within the test should be sentences and describe what is really happening within the test. The test should document itself to a certain degree. Doing this really iterates to you and other analysts the behavior of different machinery in the code, especially when written using language the business users can understand. There are even tools such as agiledox which will create simple documentation based on the class and method names within your test harness. One issue that somewhat irks me is the encouragement of long method names with this methodology. In the past I have typically put an effort into making method names as concise as possible. This practice will sometimes force you to literally write sentences in your method names, and yes, sometimes this will lead to some visually displeasing test code. In the end though, I suppose it is in fact better to be more descriptive in your test names so that you can quickly know what did not work when a test failed.
Another issue the sentence template addresses is pointing out behavior which does not belong in a certain class. An example Dan uses is calculating ages of a client. If you keep testing to make sure the client's age lines up with the client's birthdate, does it not make more sense to factor that behavior out into an AgeCalculator class? These created classes are meant to only perform a service. They are easy to test, and they are very easy to inject into classes which need the service. This is known as dependency injection (or at least a form of it).
Each test should describe a behavior. Each test is a behavior. What happens if a test fails? Well, first of all why did it fail? Did the behavior move to another class? Did the specification change such that the failed behavior is no longer relevant? When you start to think in terms of behaviors instead of "test", it really allows you to understand why you are testing and gives your code some backbone as to why things are the way they are.
One very interesting technique is how Dan integrates BDD with user stories. I know when I first started created user stories (I am still new to the idea), I had a difficult time creating a mental template on which to model them. Dan offers the following form :
+Scenario 1: A trader is alerted of status
Given a stock and a threshold of 15.0
When stock is traded at 5.0
Then the alert status should be OFF
When stock is traded at 16.0
Then the alert status should be ON
He uses a Given->When->Then schematic to what should happen in certain scenarios. In his replacement for JUnit, JBehave, we can really see how he applies this model right into the creation of tests. There are five steps: 1. Write story, 2. Map steps to Java, 3. Configure Stories, and 4. Run Stories. I have shown the second step below from his website just to show how well the stories map to the JBehave test harness.
 The idea is that each "Given" in the user story will map to a class in JBehave, so that the behavior of that story can be tested individually, which is a very, very cool idea. Also, having classes to implement these fragments allow them to be reused later as you continue to build the application, so that you will truly have well-defined end-to-end tests by the time you finish the application.
The idea is that each "Given" in the user story will map to a class in JBehave, so that the behavior of that story can be tested individually, which is a very, very cool idea. Also, having classes to implement these fragments allow them to be reused later as you continue to build the application, so that you will truly have well-defined end-to-end tests by the time you finish the application.
JBehave even has a story editor in eclipse that will link to the corresponding JBehave Java method. Sometime soon I will give his system a go, simply because the concept plays so nicely with user stories. It really implies that each user story is a specific behavior, and that each behavior has a test associated with it. A lot of people might say that BDD is still TDD, but I think it is different in that it really forces you to abide by the practices created by agile development. For a novice agile developer, it makes the steps for utilizing user stories and TDD much more natural.
Over the course of this last semester, I have learned a lot about tools and best practices for software engineering and development. This includes topics such as Agile Development, TDD (Test Driven Development), Extreme Programming, and efficient use of pair programming. Most of these development practices overlap and can be used in conjunction with one another. The problem is that to someone new to these things, it all can seem a bit overwhelming.
Dan North saw these issues and created something called behavior-driven development (BDD), as described on his blog here. Over the years Dan has been teaching and running many courses over subjects involving accelerated agile and behavior-driven development. He even has a few conferences he will be teaching at over the next few months over accelerated agile development! In his words, "[BDD]... is designed to make them [agile practices] more accessible and effective for teams new to agile software delivery".
In earlier years, when Dan was trying to fine tune his agile development and TDD skills, a series of "Aha!" moments are what drove him to create BDD. First, test method names should be sentences. Even the method names within the test should be sentences and describe what is really happening within the test. The test should document itself to a certain degree. Doing this really iterates to you and other analysts the behavior of different machinery in the code, especially when written using language the business users can understand. There are even tools such as agiledox which will create simple documentation based on the class and method names within your test harness. One issue that somewhat irks me is the encouragement of long method names with this methodology. In the past I have typically put an effort into making method names as concise as possible. This practice will sometimes force you to literally write sentences in your method names, and yes, sometimes this will lead to some visually displeasing test code. In the end though, I suppose it is in fact better to be more descriptive in your test names so that you can quickly know what did not work when a test failed.
Another issue the sentence template addresses is pointing out behavior which does not belong in a certain class. An example Dan uses is calculating ages of a client. If you keep testing to make sure the client's age lines up with the client's birthdate, does it not make more sense to factor that behavior out into an AgeCalculator class? These created classes are meant to only perform a service. They are easy to test, and they are very easy to inject into classes which need the service. This is known as dependency injection (or at least a form of it).
Each test should describe a behavior. Each test is a behavior. What happens if a test fails? Well, first of all why did it fail? Did the behavior move to another class? Did the specification change such that the failed behavior is no longer relevant? When you start to think in terms of behaviors instead of "test", it really allows you to understand why you are testing and gives your code some backbone as to why things are the way they are.
One very interesting technique is how Dan integrates BDD with user stories. I know when I first started created user stories (I am still new to the idea), I had a difficult time creating a mental template on which to model them. Dan offers the following form :
+Scenario 1: A trader is alerted of status
Given a stock and a threshold of 15.0
When stock is traded at 5.0
Then the alert status should be OFF
When stock is traded at 16.0
Then the alert status should be ON
He uses a Given->When->Then schematic to what should happen in certain scenarios. In his replacement for JUnit, JBehave, we can really see how he applies this model right into the creation of tests. There are five steps: 1. Write story, 2. Map steps to Java, 3. Configure Stories, and 4. Run Stories. I have shown the second step below from his website just to show how well the stories map to the JBehave test harness.
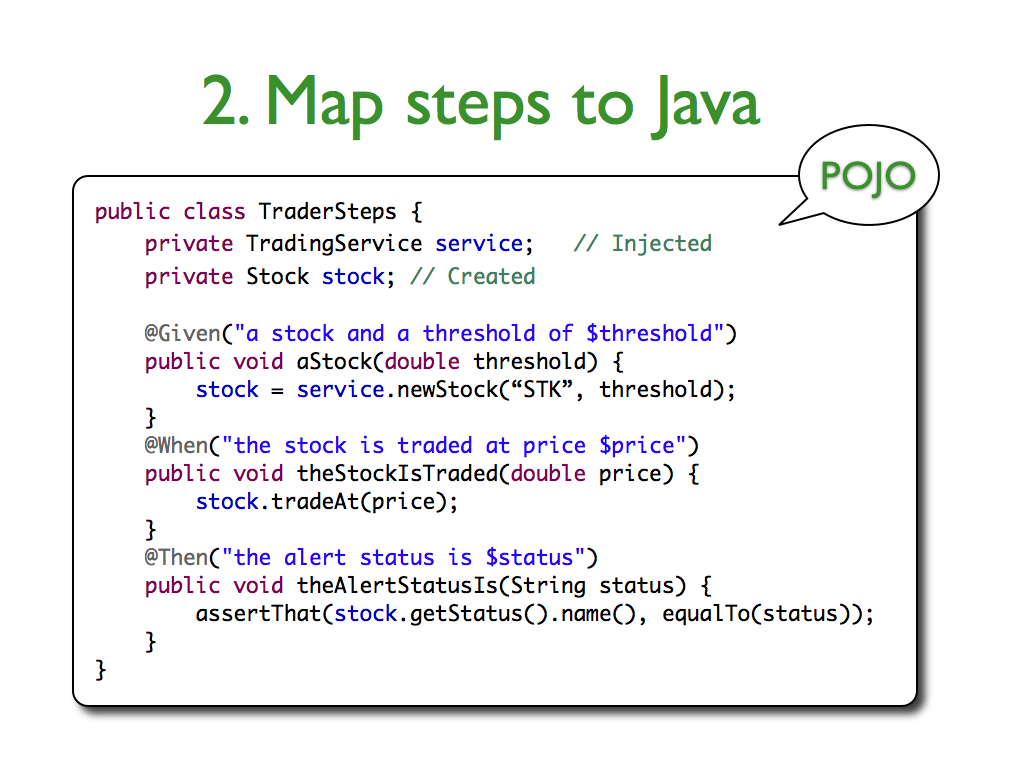
JBehave even has a story editor in eclipse that will link to the corresponding JBehave Java method. Sometime soon I will give his system a go, simply because the concept plays so nicely with user stories. It really implies that each user story is a specific behavior, and that each behavior has a test associated with it. A lot of people might say that BDD is still TDD, but I think it is different in that it really forces you to abide by the practices created by agile development. For a novice agile developer, it makes the steps for utilizing user stories and TDD much more natural.
Sunday, December 2, 2012
Using __dict__ in Python and Private Attributes
In the last phase of the World Crises project, I was designed with creating the search functionality. Given the reasonable amount of data types in our Google app engine datastore, I soon tried to search out a way to iterate over the datastore without creating multiple loops with the same body. The problem is that these types are represented as fields of different app engine model objects. How would someone iterate over the instance fields of a class?
Well, the solution I came up with was to use the __dict__ variable in python. __dict__ is a "private" (Is anything really private in Python?) variable which contains the attributes in a class instance: all functions, variables, etc. Using this special field I am able to make a list of the model names I want to search, and then access them using the __dict__ dictionary.
Why does the variable start with two underscores? This is how private attributes are handled in Python. They aren't actually private, of course, because you can still access them, but they do lend themselves to be fairly awkward and ugly if you do try to use them. If you try to create attributes that start with two underscores, they will have their names mangled like so:
>>> class A:
... def __init__(self) :
... self.__x = 5
...
>>> A().__x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: A instance has no attribute '__x'
>>> A()._A__x
5
Well, the solution I came up with was to use the __dict__ variable in python. __dict__ is a "private" (Is anything really private in Python?) variable which contains the attributes in a class instance: all functions, variables, etc. Using this special field I am able to make a list of the model names I want to search, and then access them using the __dict__ dictionary.
Why does the variable start with two underscores? This is how private attributes are handled in Python. They aren't actually private, of course, because you can still access them, but they do lend themselves to be fairly awkward and ugly if you do try to use them. If you try to create attributes that start with two underscores, they will have their names mangled like so:
>>> class A:
... def __init__(self) :
... self.__x = 5
...
>>> A().__x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: A instance has no attribute '__x'
>>> A()._A__x
5
As you can see, if you try and make a variable starting with two underscores yourself, Python will mangle it by prepending an underscore with the class name. Another interesting thing is that names starting with _ will not be imported with "from X import *".
The more you know...
Monday, November 19, 2012
Generating Search Results in Python
In the last phase of our project in CS 373, we are being asked to create a search feature in our website to search for data within the Google data store. Given that I have never done something like this before, a lot of questions arise: What tools and API's are already out there, so I don't reinvent the wheel? Should I retrieve single results at a time, or all of them at once? In our position, I believe the best way to do this is to do it ourselves.
When I took CS 307 my freshman year at UT, a guest speaker from Yahoo came and talked to us a little bit about generating search results and what they were doing to optimize their searches. The main optimization I remember was generating the results on a by-request basis. If the search page only asks for 10 results, only get the first 10 results. Since we are doing this project in Python, what better way than to do this with generators!
Really, the way we do our searches involves searching the data store for a certain query and yielding those results to the owner of the generator. It's perfect! If the search page wants 10 results, it can simply call .next() on the generator 10 times (assuming there are actually 10 results). If the user clicks 'next' on the web page, it can simply ask for another 10 as it pleases. For a project of our scale, it also allows us to prioritize our search by deciding which results get yielded first. For instance, if somebody searches "colorado", we would want the page for "Colorado Wildfires" to come up first, not where "colorado" simply comes up in the description of something else.
When I took CS 307 my freshman year at UT, a guest speaker from Yahoo came and talked to us a little bit about generating search results and what they were doing to optimize their searches. The main optimization I remember was generating the results on a by-request basis. If the search page only asks for 10 results, only get the first 10 results. Since we are doing this project in Python, what better way than to do this with generators!
Really, the way we do our searches involves searching the data store for a certain query and yielding those results to the owner of the generator. It's perfect! If the search page wants 10 results, it can simply call .next() on the generator 10 times (assuming there are actually 10 results). If the user clicks 'next' on the web page, it can simply ask for another 10 as it pleases. For a project of our scale, it also allows us to prioritize our search by deciding which results get yielded first. For instance, if somebody searches "colorado", we would want the page for "Colorado Wildfires" to come up first, not where "colorado" simply comes up in the description of something else.
Sunday, November 11, 2012
My New Perspective on Bug-Free Code
As some may know, I had the pleasure of spending Friday night and most of Saturday in the hospital. Disclaimer: I'm fine, just have a little something called Athletic Heart Syndrome and 8 stitches in my eye from fainting and introducing my face to the ground at Pho Saigon on North Lamar Friday night. Anyways, while the experience itself was pretty awful, my programming mind could not help but be in awe of the vast amounts of software around me that keep everything running smoothly.
The software on the electrocardiogram displays information about my heart and lets me and the staff know how many times my heart misses beats and stores this information the entire time I am there. Alarms are constantly being fired from different devices as the result of hardware communicating with software that something important has happened. It is imperative that the software running on these devices work absolutely as they are understood to. If somebody's heart stops and no one is alerted, I think we have a serious software issue! (Assuming the alarm happens at the software level)
I had the pleasure of having a sonogram, which is basically an ultrasound of the heart. Seriously, the software running on this machine was incredible. The nurse could click on different parts of my heart, and it would say how long each part of my heart was, it could differentiate between in and out flow color coded by red and blue. Of course the hardware is also very impressive, but being a programmer I can understand the amount of research and work that must have gone into designing that. If the software wrongly interpreted the data coming from the hardware, we could end up with false positives or negatives. I would imagine in a medical situation both of these are bad things. False positives mean that the patient could go home thinking he or she is fine when really that person has issues. False negatives mean that the patient could undergo expensive and possibly harmful treatment to a person that is actually o.k.
At the base of it, software in the medical world really has a low margin for error. How would you feel if a bug in software you wrote caused harm, even fatal harm, to another human being? Take a look at the Therac-25. It is a radiation therapy machine involved in at least 6 incidents between 1985-1987 because of a race condition with a byte counter that often overflowed. The other thing you might ask is: Is there really any code that isn't bug free? Well, when you write code, you introduce bugs. That's life, but we can minimize and reduce these bugs by following proper software engineering techniques and really believing in them. When you test, test as if someone's life depended on it. When you are getting ready to release software, ask yourself if someone's life were dependent on the software working correctly that they would be o.k. I would really like to see what kind of software engineering workflows are used in medical software and other life-dependent software such as aviation controls.
When you "buy into" some aspect of an engineering workflow like Test-Driven Development, treat it as if someone's life were dependent on it. That is what medical software engineers have to do, and I imagine it will make you a much more serious programmer if you treat it like they have to.
The software on the electrocardiogram displays information about my heart and lets me and the staff know how many times my heart misses beats and stores this information the entire time I am there. Alarms are constantly being fired from different devices as the result of hardware communicating with software that something important has happened. It is imperative that the software running on these devices work absolutely as they are understood to. If somebody's heart stops and no one is alerted, I think we have a serious software issue! (Assuming the alarm happens at the software level)
I had the pleasure of having a sonogram, which is basically an ultrasound of the heart. Seriously, the software running on this machine was incredible. The nurse could click on different parts of my heart, and it would say how long each part of my heart was, it could differentiate between in and out flow color coded by red and blue. Of course the hardware is also very impressive, but being a programmer I can understand the amount of research and work that must have gone into designing that. If the software wrongly interpreted the data coming from the hardware, we could end up with false positives or negatives. I would imagine in a medical situation both of these are bad things. False positives mean that the patient could go home thinking he or she is fine when really that person has issues. False negatives mean that the patient could undergo expensive and possibly harmful treatment to a person that is actually o.k.
At the base of it, software in the medical world really has a low margin for error. How would you feel if a bug in software you wrote caused harm, even fatal harm, to another human being? Take a look at the Therac-25. It is a radiation therapy machine involved in at least 6 incidents between 1985-1987 because of a race condition with a byte counter that often overflowed. The other thing you might ask is: Is there really any code that isn't bug free? Well, when you write code, you introduce bugs. That's life, but we can minimize and reduce these bugs by following proper software engineering techniques and really believing in them. When you test, test as if someone's life depended on it. When you are getting ready to release software, ask yourself if someone's life were dependent on the software working correctly that they would be o.k. I would really like to see what kind of software engineering workflows are used in medical software and other life-dependent software such as aviation controls.
When you "buy into" some aspect of an engineering workflow like Test-Driven Development, treat it as if someone's life were dependent on it. That is what medical software engineers have to do, and I imagine it will make you a much more serious programmer if you treat it like they have to.
Sunday, November 4, 2012
How to Study for Dr. Downing's Exams
Last week I learned a few valuable lessons, and for once I learned them in a good way. See, typically I do not do well on Dr. Downing's exams. They tend to feed off the things I almost know and should know, but just quite can't extract from the tip of my tongue. I always do well on the projects, go up and down with the quizzes, but the tests for me are always a wildcard. This one was different...
Friday, a networks project was due, and being that I was going mountain bike racing for the weekend come lunchtime Friday, I knew things were going to get a little hectic Wednesday and Thursday. During crunch time on Thursday afternoon, I think I found the best way to study Dr. Downing's test:
Fire up the Python interpreter and just start cranking examples.
Seriously. Go through all the slides. Define functions. Define new functions. Do them backwards. Now forwards. Upside-down. Do stupid examples, even things that you would normally think to be common sense because come test time, you very well might not know slight pythonic nuances simply because you've never dealt with them yourself. It's one thing to see things done for you in class, it's another thing to do them yourself. I'll say it again:
It's one thing to see things done for you in class, it's another thing to do them yourself.
Also, be a good boy and do the reading. Dr. Downing's readings are extremely helpful and respectably applicable to the real world. Not only will they help you become a more understanding programmer, but they most certainly will also score you a couple test answers.
This was probably the first test I've felt comfortable with, and it's simply from running through examples myself instead of just looking at them. Cheers!
Friday, a networks project was due, and being that I was going mountain bike racing for the weekend come lunchtime Friday, I knew things were going to get a little hectic Wednesday and Thursday. During crunch time on Thursday afternoon, I think I found the best way to study Dr. Downing's test:
Fire up the Python interpreter and just start cranking examples.
Seriously. Go through all the slides. Define functions. Define new functions. Do them backwards. Now forwards. Upside-down. Do stupid examples, even things that you would normally think to be common sense because come test time, you very well might not know slight pythonic nuances simply because you've never dealt with them yourself. It's one thing to see things done for you in class, it's another thing to do them yourself. I'll say it again:
It's one thing to see things done for you in class, it's another thing to do them yourself.
Also, be a good boy and do the reading. Dr. Downing's readings are extremely helpful and respectably applicable to the real world. Not only will they help you become a more understanding programmer, but they most certainly will also score you a couple test answers.
This was probably the first test I've felt comfortable with, and it's simply from running through examples myself instead of just looking at them. Cheers!
Sunday, October 28, 2012
Keyword Argument Unpacking in Python
Recently in Software Engineering we learned about "keyword argument unpacking" in Python. Many times when I learn weird language quirks and features like this, I often think about how the language feature can help the design of my program flow in a natural way; more natural than if the feature did not exist in the first place.
Keyword argument unpacking basically works by "decorating" the name of a dictionary with two prefixed asterisks in a function or method call which has argument keywords that have the same strings as the keys of the dictionary.
So basically, say we have the following function:
def f (x, y, z) :
return [x, y, z]
We can make the following call:
f(dict([(x, 1), (y, 2), (z, 4)])
Or the following call:
f(dict([(y, 2), (z, 4), (x, 1)])
Or in any other order and still got the same list back: [1, 2, 4]
Last wee this proved to be particularly useful in dealing with Google App Engine models mainly because the models can often be constructed with a subset of possible arguments. If you only want one call to the model constructor and the number of arguments is dynamic at runtime, then simply building a dictionary with the arguments and values of the call seems to be a very elegant solution. Before I thought to use it, I had a very ugly block with many if and else statements creating different models depending on which arguments to the model constructor were valid. Again, this way is much more elegant. It is limited, but I do believe I have found one of my new favorite features of Python.
Keyword argument unpacking basically works by "decorating" the name of a dictionary with two prefixed asterisks in a function or method call which has argument keywords that have the same strings as the keys of the dictionary.
So basically, say we have the following function:
def f (x, y, z) :
return [x, y, z]
We can make the following call:
f(dict([(x, 1), (y, 2), (z, 4)])
Or the following call:
f(dict([(y, 2), (z, 4), (x, 1)])
Or in any other order and still got the same list back: [1, 2, 4]
Last wee this proved to be particularly useful in dealing with Google App Engine models mainly because the models can often be constructed with a subset of possible arguments. If you only want one call to the model constructor and the number of arguments is dynamic at runtime, then simply building a dictionary with the arguments and values of the call seems to be a very elegant solution. Before I thought to use it, I had a very ugly block with many if and else statements creating different models depending on which arguments to the model constructor were valid. Again, this way is much more elegant. It is limited, but I do believe I have found one of my new favorite features of Python.
Sunday, October 21, 2012
Editors vs IDE's in a Group Environment
Last semester in Object Oriented Programming I touched on this subject a bit in my blog there, but now that I've gotten the chance to assess this subject from a group's perspective, I thought I would give it another shot.
Both editors and IDE's (Interactive Development Environments) have their place. People will moan over how editors are "so superior" to IDE's in every way, but the simple truth is that some things are just better done in a full blown IDE. In smaller projects and most projects done by myself, I will choose to do them with vim (the best editor :) ). I can search and/or replace faster than you can blink, I can move around the document painlessly, and basically any unix machine around will have it. Combine it with a terminal multiplexer like tmux, (which is also installed on all the CS linux machines thanks to me) and you have got yourself a serious development setup.
The thing is though, this really only works for small jobs. When I say small, I mean within a week, maybe a couple weeks of time to finish a project. I love working with vim, but when the projects get large with oodles of different files and formats, using a terminal with a lighweight editor just for the hell of it can get a little cumbersome. The truth is that the developers of these IDE's just put too many awesome features in them for the large scale projects to pass up. In a group environment often times some people just are not extremely comfortable with editors yet, and to be honest they can be a little intimidating to some who are not used to them.
The current project for Software Engineering calls for the creation of an XML schema, an XML file which uses the schema, and the translation of the xml into Google App models, which will be used to display web pages interfacing with the models. In my experience, it is extremely important to establish the environments the group will be working with early on so that each member of the group can help each other with any environment problems, and so the rest of the time can be spent working on developing.
So what did we choose? Eclipse of course! In our case, we chose Eclipse for Java EE Developers, which is really an Eclipse package which includes a ton of awesome tools for Web Development. Eclipse is cross-platform, so we can use it on our Linux, Windows, and OS X machines without a problem. We then all installed eGit, which is a Git plugin for Eclipse so we can communicate with our Git repository on GitHub. This really made the creation of the XML a breeze and allowed us all the ability to essentially work in the same environment regardless of what systems we were running. We also installed the PyDev plugin for eclipse and the Google App SDK so we could also run whatever Python code we needed from within Eclipse. As an extra touch I also installed a vi-binding plugin so that I could get a similar feel to vim within Eclipse.
Could we have done this all in our own separate environments? Probably. Could we have done it as quickly? Questionable. Granted, it did take me quite a bit of time to establish what I thought would be a good environment for the team based on my experience, but it definitely paid off. We were able to work in a more uniform manner, communicate more effectively, and use some awesome new tools!
Both editors and IDE's (Interactive Development Environments) have their place. People will moan over how editors are "so superior" to IDE's in every way, but the simple truth is that some things are just better done in a full blown IDE. In smaller projects and most projects done by myself, I will choose to do them with vim (the best editor :) ). I can search and/or replace faster than you can blink, I can move around the document painlessly, and basically any unix machine around will have it. Combine it with a terminal multiplexer like tmux, (which is also installed on all the CS linux machines thanks to me) and you have got yourself a serious development setup.
The thing is though, this really only works for small jobs. When I say small, I mean within a week, maybe a couple weeks of time to finish a project. I love working with vim, but when the projects get large with oodles of different files and formats, using a terminal with a lighweight editor just for the hell of it can get a little cumbersome. The truth is that the developers of these IDE's just put too many awesome features in them for the large scale projects to pass up. In a group environment often times some people just are not extremely comfortable with editors yet, and to be honest they can be a little intimidating to some who are not used to them.
The current project for Software Engineering calls for the creation of an XML schema, an XML file which uses the schema, and the translation of the xml into Google App models, which will be used to display web pages interfacing with the models. In my experience, it is extremely important to establish the environments the group will be working with early on so that each member of the group can help each other with any environment problems, and so the rest of the time can be spent working on developing.
So what did we choose? Eclipse of course! In our case, we chose Eclipse for Java EE Developers, which is really an Eclipse package which includes a ton of awesome tools for Web Development. Eclipse is cross-platform, so we can use it on our Linux, Windows, and OS X machines without a problem. We then all installed eGit, which is a Git plugin for Eclipse so we can communicate with our Git repository on GitHub. This really made the creation of the XML a breeze and allowed us all the ability to essentially work in the same environment regardless of what systems we were running. We also installed the PyDev plugin for eclipse and the Google App SDK so we could also run whatever Python code we needed from within Eclipse. As an extra touch I also installed a vi-binding plugin so that I could get a similar feel to vim within Eclipse.
Could we have done this all in our own separate environments? Probably. Could we have done it as quickly? Questionable. Granted, it did take me quite a bit of time to establish what I thought would be a good environment for the team based on my experience, but it definitely paid off. We were able to work in a more uniform manner, communicate more effectively, and use some awesome new tools!
Sunday, October 14, 2012
Pickles in Python
In the last project for Software Engineering, Netflix, we were asked to guess the ratings different users would give to different movies based on information from a large dataset of users, movies, and ratings. Sadly, for this project I was forced to work alone, and I knew I needed to be as efficient as possible in order to get done in time. The project called for different caches from the data: average ratings for different users, average ratings for different movies, standard deviations of users' ratings from their mean rating, average ratings from a user per decade (which decade the movie was in). Needless to say, parsing all this data could have been a real chore if I was not careful, and not just parsing it, but outputting it (caching it) into a format my top-level application could read later.
Recently at my job, the application I am creating called for Object serialization, which is basically a way in which Object instances in a running application can be "serialized" and output through some kind of data stream, usually a file. I knew something had to exist in Python for object serialization, so I came to find out about Pickle, which is exactly that.
Now to the fun stuff...
Pickle basically allows us to write any data structure to a file like so :
import pickle
my_list = ['f', 'o', 'o', 'e', 'y']
pickle.dump(my_list, open('my_list.p', 'w'))
That's it! And it is an awfully nice way to store the caches for the Netflix project. We can simply read these serialized objects back in like so:
import pickle
my_list = pickle.load(open('my_list.p', 'r'))
Again, that's it! Immediately our list (or any other data structure we save) is loaded right back into memory, ready to be used by the application. There is no ugly parsing of my own hacked-together data format, it is just the beauty of serialized objects and me saving a ton of time.
Speaking of saving time, we can actually save even more time in the code by changing the import statement from :
import pickle
to:
import cPickle as pickle
This imports the cPickle module instead of the standard pickle module. The difference is that cPickle is written in C and is "up to 1000 times faster" than the Python version of pickle. You lose out on some of the subclassibility of the normal pickle, but hey, you can't argue with 1000 times faster.
Object serialization really is a beautiful thing!
Cheers
Recently at my job, the application I am creating called for Object serialization, which is basically a way in which Object instances in a running application can be "serialized" and output through some kind of data stream, usually a file. I knew something had to exist in Python for object serialization, so I came to find out about Pickle, which is exactly that.
Now to the fun stuff...
Pickle basically allows us to write any data structure to a file like so :
import pickle
my_list = ['f', 'o', 'o', 'e', 'y']
pickle.dump(my_list, open('my_list.p', 'w'))
That's it! And it is an awfully nice way to store the caches for the Netflix project. We can simply read these serialized objects back in like so:
import pickle
my_list = pickle.load(open('my_list.p', 'r'))
Again, that's it! Immediately our list (or any other data structure we save) is loaded right back into memory, ready to be used by the application. There is no ugly parsing of my own hacked-together data format, it is just the beauty of serialized objects and me saving a ton of time.
Speaking of saving time, we can actually save even more time in the code by changing the import statement from :
import pickle
to:
import cPickle as pickle
This imports the cPickle module instead of the standard pickle module. The difference is that cPickle is written in C and is "up to 1000 times faster" than the Python version of pickle. You lose out on some of the subclassibility of the normal pickle, but hey, you can't argue with 1000 times faster.
Object serialization really is a beautiful thing!
Cheers
Monday, October 8, 2012
Design Trade-Offs
After reading Is Design Dead?, I have come to realize the debates that exist over the amount of effort and thoroughness that should be put into the design stage of XP. XP really encourages that design really be indirectly created through the development of user stories, and that designs really should not be "set in stone" when development begins.
When I started my first large project in the summer with ARM, I more or less took the XP approach. I had no idea what issues I would come across in development, and I really had no idea what classes and structures were necessary to complete the job. And that's ok! So I thought. The design would sort itself out in the end.
There's a balance though. There needs to be some element of design pattern application and forethought structure put in place such that refactoring and scalability will not be an issue later. You can't just go aimlessly writing hundreds of lines of code implementing spike solutions to user stories. There still needs to be some thought put into design so that when it comes time to improve the solution, you won't have to rewrite the entire thing.
Again, for my project, I had no idea what problems I would come across, so I sort of formed a "design-as-you-go" mentality. Keep design as simple as possible and as scalable as possible. The design should make sense from an overhead view and should be fluently applicable at the source code view. As the project grows in scope, it can be difficult to balance the work put into design and the work put into user stories. How much time do I spend refactoring code in order to adhere to a better design? In my experience, if I think that a certain piece of code will need to be expanded on later, I tend to spend a good amount of time on refactoring it if I believe there is a better design. Often times there is just no way I would have known why this new thought out design was better, so there is no way I could have designed it in the first place.
Sometimes people can get really attached to pre-determined designs and force code to adhere to it. The problem is that the code will begin to lose its flow and explaining it to someone else will become more and more confusing. If you can't explain the overall flow to someone, it's probably a bad idea, and it is due to bad design, the design needs to be modified.
Just as people shouldn't get too attached to code, don't get too attached to design! In my opinion, software design is just as important as the code itself, and if it needs to be changed for the better, by all means just do it! Cross it out with a pen! If you force yourself to adhere to a bad pre-determined design, you are going to have a bad time.
When I started my first large project in the summer with ARM, I more or less took the XP approach. I had no idea what issues I would come across in development, and I really had no idea what classes and structures were necessary to complete the job. And that's ok! So I thought. The design would sort itself out in the end.
There's a balance though. There needs to be some element of design pattern application and forethought structure put in place such that refactoring and scalability will not be an issue later. You can't just go aimlessly writing hundreds of lines of code implementing spike solutions to user stories. There still needs to be some thought put into design so that when it comes time to improve the solution, you won't have to rewrite the entire thing.
Again, for my project, I had no idea what problems I would come across, so I sort of formed a "design-as-you-go" mentality. Keep design as simple as possible and as scalable as possible. The design should make sense from an overhead view and should be fluently applicable at the source code view. As the project grows in scope, it can be difficult to balance the work put into design and the work put into user stories. How much time do I spend refactoring code in order to adhere to a better design? In my experience, if I think that a certain piece of code will need to be expanded on later, I tend to spend a good amount of time on refactoring it if I believe there is a better design. Often times there is just no way I would have known why this new thought out design was better, so there is no way I could have designed it in the first place.
Sometimes people can get really attached to pre-determined designs and force code to adhere to it. The problem is that the code will begin to lose its flow and explaining it to someone else will become more and more confusing. If you can't explain the overall flow to someone, it's probably a bad idea, and it is due to bad design, the design needs to be modified.
Just as people shouldn't get too attached to code, don't get too attached to design! In my opinion, software design is just as important as the code itself, and if it needs to be changed for the better, by all means just do it! Cross it out with a pen! If you force yourself to adhere to a bad pre-determined design, you are going to have a bad time.
Monday, October 1, 2012
Test Driven Development
Last week we had a visitor from National Instruments come and speak to our class about the company and how they implement different forms of test driven development. In every case where it was used in previous projects it was a great access, but a few issues were shown that can make it somewhat difficult to implement. (Ones I have had issues with in the past as well)
1. Getting everybody on board with test driven development can be a real chore, especially if the project manager is hard-coded with old fashion methodologies which say to test later.
2. Sometimes it is difficult to test code which belongs to someone else. When developing a front end or application which depends on other databases, it is sometimes impossible to test the database communication functions independently. Sometimes top-level acceptance type tests are only possible, and that's ok! At least the entire system is testable.
3. It is difficult to test when the project outcome was not defined well enough when the test writing began. Let's say for instance you write 100 tests based on a particular understanding of what the correct output is. If the project manager keeps coming in and saying, "I know we created those stories a month ago, but the output needs to change again", it starts to get very annoying. When the consumer/manager/person who wants the application to exist keeps dramatically changing his or her mind about the scope of the project, the will for developers to effectively test can really be impacted. Establish scope first!
These are just a few, but the first and third of these examples are two of the reasons why I personally have trouble with test driven development. I will say it is the way to go. The representative from NI (National Instruments) really showed me to push myself to be in better communication with my manager and learn to persuade the company of things I truly believe will help. TDD is definitely one of those things and should make my job much easier.
1. Getting everybody on board with test driven development can be a real chore, especially if the project manager is hard-coded with old fashion methodologies which say to test later.
2. Sometimes it is difficult to test code which belongs to someone else. When developing a front end or application which depends on other databases, it is sometimes impossible to test the database communication functions independently. Sometimes top-level acceptance type tests are only possible, and that's ok! At least the entire system is testable.
3. It is difficult to test when the project outcome was not defined well enough when the test writing began. Let's say for instance you write 100 tests based on a particular understanding of what the correct output is. If the project manager keeps coming in and saying, "I know we created those stories a month ago, but the output needs to change again", it starts to get very annoying. When the consumer/manager/person who wants the application to exist keeps dramatically changing his or her mind about the scope of the project, the will for developers to effectively test can really be impacted. Establish scope first!
These are just a few, but the first and third of these examples are two of the reasons why I personally have trouble with test driven development. I will say it is the way to go. The representative from NI (National Instruments) really showed me to push myself to be in better communication with my manager and learn to persuade the company of things I truly believe will help. TDD is definitely one of those things and should make my job much easier.
Saturday, September 22, 2012
Some Python Nuances
Me and my partner have been struggling a little bit with the current project due to some misunderstood Python nuances. Our current implementation to the Project File Dependencies problem on Sphere calls for a list of lists. Seems like standard procedure right? We should just use Python's overloaded * operator to initialize the data structure like so:
matrix_size = 5
matrix = [[]] * matrix_size
Which, if we print out the matrix, we get the following output:
[[], [], [], [], []]
It seems like it is working just fine, but if we do a simple operation, like add a number to the list at index 0, funny things start to happen. See the following operation:
matrix[0].append("?")
and the contents of the matrix afterwards:
[['?'], ['?'], ['?'], ['?'], ['?']]
How does this make sense? What were the creators of Python thinking? Why does this functionality make sense? I do not understand why this is the case. It is acting like each list in the matrix is just a reference to one matrix. In order to get the functionality we wanted we had to do something like the following:
matrix = [[] for i in range(matrix_size)]
which seems to be working just fine because a new list is created for each index.
Another issue we were having lies in the annoyance that Python has no increment or decrement operators! And if you try to use them, nothing happens! It is valid Python syntax!
It is all ok though. With every new language comes a little bit of headache. As far as interpreted languages go, Python is coming to be one of my favorites so far, and as long as I can minimize future headaches like the first one in this post I think I will be quite alright.
matrix_size = 5
matrix = [[]] * matrix_size
Which, if we print out the matrix, we get the following output:
[[], [], [], [], []]
It seems like it is working just fine, but if we do a simple operation, like add a number to the list at index 0, funny things start to happen. See the following operation:
matrix[0].append("?")
and the contents of the matrix afterwards:
[['?'], ['?'], ['?'], ['?'], ['?']]
How does this make sense? What were the creators of Python thinking? Why does this functionality make sense? I do not understand why this is the case. It is acting like each list in the matrix is just a reference to one matrix. In order to get the functionality we wanted we had to do something like the following:
matrix = [[] for i in range(matrix_size)]
which seems to be working just fine because a new list is created for each index.
Another issue we were having lies in the annoyance that Python has no increment or decrement operators! And if you try to use them, nothing happens! It is valid Python syntax!
It is all ok though. With every new language comes a little bit of headache. As far as interpreted languages go, Python is coming to be one of my favorites so far, and as long as I can minimize future headaches like the first one in this post I think I will be quite alright.
Monday, September 17, 2012
Write Tests Before Development
In my recent programming travels at work I have come across an increasing problem: Communicating the importance of testing to the project manager. Sometimes, oddly enough, the manager does not allocate time for testing in the development cycle, and simply accepts a spike solution as the final solution and asks for more features.
To a project group not accustomed to the methods of Extreme Programming, how does one communicate the effectiveness of the programming methodology to his or her peers? In my opinion it is simple, you just do it anyway.
Sure, the manager might moan about how it is taking you a little longer to get things "complete", but the difference is code that "somewhat provably works in all possible cases" versus code that "works in a small demo and might work in more cases". Writing tests first makes sense for a variety of reasons. First, it allows you to define the exact purpose of a method or function by testing different inputs on defined outputs. Every time I change or refactor some code in a class, I don't want to have to open up the GUI and click through different execution paths just to test some small method. Writing the tests first also allows you to double check a story with the "customer" who created the story (In my case the manager) and make sure the expected output is really what is expected. My final reason for writing the tests first is that you won't be tempted into not writing them later. A lot of times when we write code and build on it we can get the illusion that the building block classes that make up the outer level tested class work correctly, which might not necessarily be the case. If someone writes another api or class that utilizes an untested class, it opens up the door for new execution paths which can introduce new bugs.
Always test your code. Test first, and your life will be much easier later on in the development cycle. I can't stress it enough!
To a project group not accustomed to the methods of Extreme Programming, how does one communicate the effectiveness of the programming methodology to his or her peers? In my opinion it is simple, you just do it anyway.
Sure, the manager might moan about how it is taking you a little longer to get things "complete", but the difference is code that "somewhat provably works in all possible cases" versus code that "works in a small demo and might work in more cases". Writing tests first makes sense for a variety of reasons. First, it allows you to define the exact purpose of a method or function by testing different inputs on defined outputs. Every time I change or refactor some code in a class, I don't want to have to open up the GUI and click through different execution paths just to test some small method. Writing the tests first also allows you to double check a story with the "customer" who created the story (In my case the manager) and make sure the expected output is really what is expected. My final reason for writing the tests first is that you won't be tempted into not writing them later. A lot of times when we write code and build on it we can get the illusion that the building block classes that make up the outer level tested class work correctly, which might not necessarily be the case. If someone writes another api or class that utilizes an untested class, it opens up the door for new execution paths which can introduce new bugs.
Always test your code. Test first, and your life will be much easier later on in the development cycle. I can't stress it enough!
Sunday, September 9, 2012
Stories in Extreme Programming
It is just recently that I have been introduced into the world of Extreme Programming. Once I was exposed during the Spring semester in Dr. Downing's Object-Oriented Programming class, and now I am really getting to dig deep into what it really means. During the first 8 chapters of Extreme Programming Installed the authors stressed the concept of stories, which are quite literally index cards on which the customer describes the function of small pieces of a focal application, and possibly some implementation.
In my current internship with ARM, this concept has been extremely helpful in encouraging complete and thorough communication between me and the customer, which is actually the "project manager". Basically a two man team, I write all code-related things and he simply communicates what he wants to happen on my whiteboard. He knows exactly what he wants the application to do. He is not a software developer (that's my job!), but it is up to me to interpret the functionality he desires and portray it in the most effective and scale-able way possible. Everyday, it is a conglomeration of new stories on the whiteboard. Some are trashed, some rewritten, some split up into different stories, and some finished.
I understand it is not quite a stack of index cards like the book suggests, but the idea remains the same. I am not necessarily a hardware guy, and I often struggle with understanding why things need to be done in according to how the story is written, but because my manager so effectively communicated it in the story, I am able to develop and make him and the other users of the software happy.
When I first read the assigned chapters, I found it interesting that I had already been writing stories unknowingly all along. I have also found that when you, the developer, start writing the stories instead of the consumer, things can get hairy fast. You might think you know what the customer/consumer wants, and while you think you know, you'll soon find that stories which are already implemented may have to be trashed pretty quickly. This is why it is important to keep your customers close. Have them right the stories, and development will happen very quickly, or as quick as you say it will.
Happy story-writing!
In my current internship with ARM, this concept has been extremely helpful in encouraging complete and thorough communication between me and the customer, which is actually the "project manager". Basically a two man team, I write all code-related things and he simply communicates what he wants to happen on my whiteboard. He knows exactly what he wants the application to do. He is not a software developer (that's my job!), but it is up to me to interpret the functionality he desires and portray it in the most effective and scale-able way possible. Everyday, it is a conglomeration of new stories on the whiteboard. Some are trashed, some rewritten, some split up into different stories, and some finished.
I understand it is not quite a stack of index cards like the book suggests, but the idea remains the same. I am not necessarily a hardware guy, and I often struggle with understanding why things need to be done in according to how the story is written, but because my manager so effectively communicated it in the story, I am able to develop and make him and the other users of the software happy.
When I first read the assigned chapters, I found it interesting that I had already been writing stories unknowingly all along. I have also found that when you, the developer, start writing the stories instead of the consumer, things can get hairy fast. You might think you know what the customer/consumer wants, and while you think you know, you'll soon find that stories which are already implemented may have to be trashed pretty quickly. This is why it is important to keep your customers close. Have them right the stories, and development will happen very quickly, or as quick as you say it will.
Happy story-writing!
Sunday, September 2, 2012
A New Beginning
Hello fellow pupils and random internet surfers, my name is Cole Stewart. I am a computer science student at the University of Texas at Austin. I took Object Oriented Programming in the Fall from Dr. Downing, and I am very excited to see what Software Engineering has to offer.
This week we talked about the first project, the Collatz Conjecture, which basically states that when given a number, if it is even, divide it by 2, and if odd, multiply by 3 and add 1. When applied repeatedly to a number, it will eventually reach 1. It is an interesting conjecture as nobody has ever actually proved it, but a counterexample has never been produced.
All in all, I am very excited about this class. I am currently working at ARM and use topics learned from Object-Oriented Programming everyday. I am a Java Swing developer, and the class really allowed me to better understand how objects communicate with one another. I am really looking forward to learning more about Python and Javascript. They are things I have always wanted to know more about, but never really had the willpower to do so. This is going to be a great semester.
This week we talked about the first project, the Collatz Conjecture, which basically states that when given a number, if it is even, divide it by 2, and if odd, multiply by 3 and add 1. When applied repeatedly to a number, it will eventually reach 1. It is an interesting conjecture as nobody has ever actually proved it, but a counterexample has never been produced.
All in all, I am very excited about this class. I am currently working at ARM and use topics learned from Object-Oriented Programming everyday. I am a Java Swing developer, and the class really allowed me to better understand how objects communicate with one another. I am really looking forward to learning more about Python and Javascript. They are things I have always wanted to know more about, but never really had the willpower to do so. This is going to be a great semester.
Subscribe to:
Posts (Atom)