Over the course of this last semester, I believe I have gained a respectable amount of exposure to techniques and industry standards in the field of software engineering. Having taken Object Oriented Programming last (Spring) semester and Software Engineering this Fall with Dr. Downing, I have learned invaluable information that will no doubt stay with me for years to come.
I believe one of the most valuable things I have learned is how to work with a group. I currently work at ARM, but I am mostly a one man show. I work with a collection of engineers that tell me what they want, and I do it. In a way, the computer engineers are my consumer, and I am constantly going back and forth with them, creating new features and determining the next feature to implement with the highest priority. Another is testing. Dr. Downing stresses and stresses test driven development. You test first, you reap the rewards. You get things done correctly. Your code changes work predictably. If you do not test first, you develop software that is half-baked. It is not guaranteed to work. You have no real way to demonstrate that your code works, and no real way to test your consistently test your changes against the established behavior of the system, and make sure it complies.
I encourage all comp-sci students at UT Austin to take Dr. Downing's class. The information he gives is truly invaluable, and he always presents it in a way that prevent you from simply slipping by. His classes are truly in-your-face and get down to the nitty-gritty of various C.S. languages. As far as I am concerned, there is no better person to learn C++ or python from. He will not only teach you the language, but he will also tell you how badly they suck. Java sucks. C++ sucks. Haskell sucks. Of course, they all have their respective benefits, but he doesn't simply begin a love story with a language when you take a class from him. He will tell you what makes the language beautiful, but will not forget to tell you what truly doesn't make sense.
All in all, I might not make extravagant grades in Dr. Downing's classes like I do in others, but I learn an incredible amount. Dr. Downing, you will truly be missed. Peace.
Sunday, December 9, 2012
Friday, December 7, 2012
Paper Blog: Behavior Driven Development
Edit: the original paper by Dan North can be found here
Over the course of this last semester, I have learned a lot about tools and best practices for software engineering and development. This includes topics such as Agile Development, TDD (Test Driven Development), Extreme Programming, and efficient use of pair programming. Most of these development practices overlap and can be used in conjunction with one another. The problem is that to someone new to these things, it all can seem a bit overwhelming.
Dan North saw these issues and created something called behavior-driven development (BDD), as described on his blog here. Over the years Dan has been teaching and running many courses over subjects involving accelerated agile and behavior-driven development. He even has a few conferences he will be teaching at over the next few months over accelerated agile development! In his words, "[BDD]... is designed to make them [agile practices] more accessible and effective for teams new to agile software delivery".
In earlier years, when Dan was trying to fine tune his agile development and TDD skills, a series of "Aha!" moments are what drove him to create BDD. First, test method names should be sentences. Even the method names within the test should be sentences and describe what is really happening within the test. The test should document itself to a certain degree. Doing this really iterates to you and other analysts the behavior of different machinery in the code, especially when written using language the business users can understand. There are even tools such as agiledox which will create simple documentation based on the class and method names within your test harness. One issue that somewhat irks me is the encouragement of long method names with this methodology. In the past I have typically put an effort into making method names as concise as possible. This practice will sometimes force you to literally write sentences in your method names, and yes, sometimes this will lead to some visually displeasing test code. In the end though, I suppose it is in fact better to be more descriptive in your test names so that you can quickly know what did not work when a test failed.
Another issue the sentence template addresses is pointing out behavior which does not belong in a certain class. An example Dan uses is calculating ages of a client. If you keep testing to make sure the client's age lines up with the client's birthdate, does it not make more sense to factor that behavior out into an AgeCalculator class? These created classes are meant to only perform a service. They are easy to test, and they are very easy to inject into classes which need the service. This is known as dependency injection (or at least a form of it).
Each test should describe a behavior. Each test is a behavior. What happens if a test fails? Well, first of all why did it fail? Did the behavior move to another class? Did the specification change such that the failed behavior is no longer relevant? When you start to think in terms of behaviors instead of "test", it really allows you to understand why you are testing and gives your code some backbone as to why things are the way they are.
One very interesting technique is how Dan integrates BDD with user stories. I know when I first started created user stories (I am still new to the idea), I had a difficult time creating a mental template on which to model them. Dan offers the following form :
+Scenario 1: A trader is alerted of status
Given a stock and a threshold of 15.0
When stock is traded at 5.0
Then the alert status should be OFF
When stock is traded at 16.0
Then the alert status should be ON
He uses a Given->When->Then schematic to what should happen in certain scenarios. In his replacement for JUnit, JBehave, we can really see how he applies this model right into the creation of tests. There are five steps: 1. Write story, 2. Map steps to Java, 3. Configure Stories, and 4. Run Stories. I have shown the second step below from his website just to show how well the stories map to the JBehave test harness.
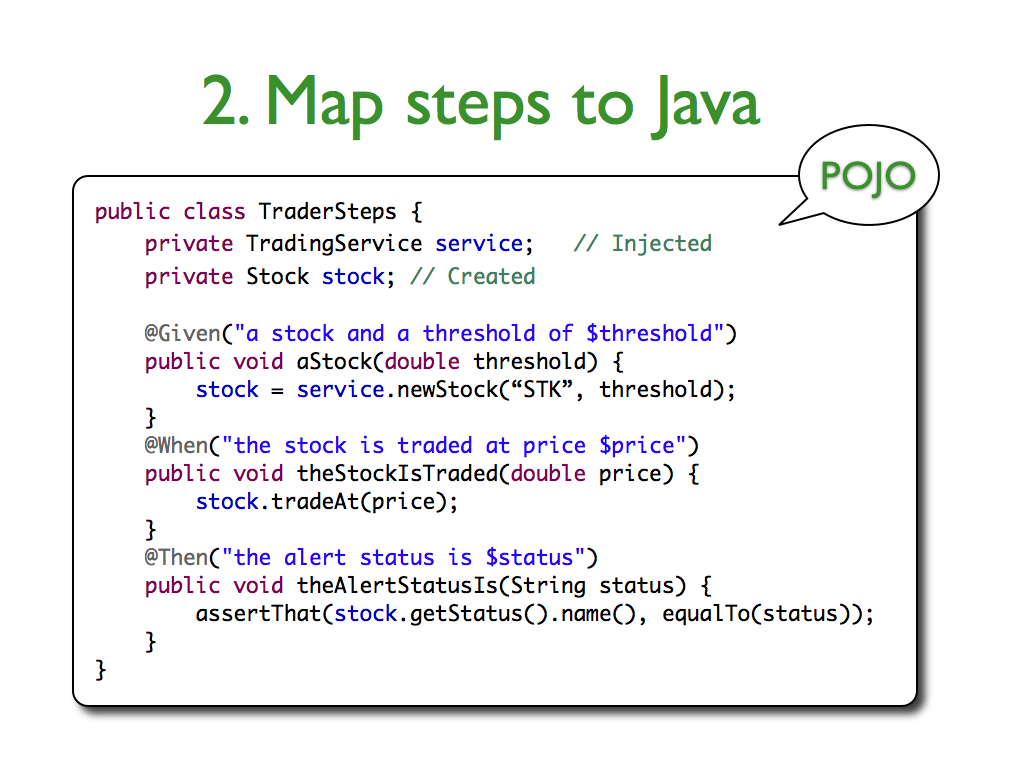 The idea is that each "Given" in the user story will map to a class in JBehave, so that the behavior of that story can be tested individually, which is a very, very cool idea. Also, having classes to implement these fragments allow them to be reused later as you continue to build the application, so that you will truly have well-defined end-to-end tests by the time you finish the application.
The idea is that each "Given" in the user story will map to a class in JBehave, so that the behavior of that story can be tested individually, which is a very, very cool idea. Also, having classes to implement these fragments allow them to be reused later as you continue to build the application, so that you will truly have well-defined end-to-end tests by the time you finish the application.
JBehave even has a story editor in eclipse that will link to the corresponding JBehave Java method. Sometime soon I will give his system a go, simply because the concept plays so nicely with user stories. It really implies that each user story is a specific behavior, and that each behavior has a test associated with it. A lot of people might say that BDD is still TDD, but I think it is different in that it really forces you to abide by the practices created by agile development. For a novice agile developer, it makes the steps for utilizing user stories and TDD much more natural.
Over the course of this last semester, I have learned a lot about tools and best practices for software engineering and development. This includes topics such as Agile Development, TDD (Test Driven Development), Extreme Programming, and efficient use of pair programming. Most of these development practices overlap and can be used in conjunction with one another. The problem is that to someone new to these things, it all can seem a bit overwhelming.
Dan North saw these issues and created something called behavior-driven development (BDD), as described on his blog here. Over the years Dan has been teaching and running many courses over subjects involving accelerated agile and behavior-driven development. He even has a few conferences he will be teaching at over the next few months over accelerated agile development! In his words, "[BDD]... is designed to make them [agile practices] more accessible and effective for teams new to agile software delivery".
In earlier years, when Dan was trying to fine tune his agile development and TDD skills, a series of "Aha!" moments are what drove him to create BDD. First, test method names should be sentences. Even the method names within the test should be sentences and describe what is really happening within the test. The test should document itself to a certain degree. Doing this really iterates to you and other analysts the behavior of different machinery in the code, especially when written using language the business users can understand. There are even tools such as agiledox which will create simple documentation based on the class and method names within your test harness. One issue that somewhat irks me is the encouragement of long method names with this methodology. In the past I have typically put an effort into making method names as concise as possible. This practice will sometimes force you to literally write sentences in your method names, and yes, sometimes this will lead to some visually displeasing test code. In the end though, I suppose it is in fact better to be more descriptive in your test names so that you can quickly know what did not work when a test failed.
Another issue the sentence template addresses is pointing out behavior which does not belong in a certain class. An example Dan uses is calculating ages of a client. If you keep testing to make sure the client's age lines up with the client's birthdate, does it not make more sense to factor that behavior out into an AgeCalculator class? These created classes are meant to only perform a service. They are easy to test, and they are very easy to inject into classes which need the service. This is known as dependency injection (or at least a form of it).
Each test should describe a behavior. Each test is a behavior. What happens if a test fails? Well, first of all why did it fail? Did the behavior move to another class? Did the specification change such that the failed behavior is no longer relevant? When you start to think in terms of behaviors instead of "test", it really allows you to understand why you are testing and gives your code some backbone as to why things are the way they are.
One very interesting technique is how Dan integrates BDD with user stories. I know when I first started created user stories (I am still new to the idea), I had a difficult time creating a mental template on which to model them. Dan offers the following form :
+Scenario 1: A trader is alerted of status
Given a stock and a threshold of 15.0
When stock is traded at 5.0
Then the alert status should be OFF
When stock is traded at 16.0
Then the alert status should be ON
He uses a Given->When->Then schematic to what should happen in certain scenarios. In his replacement for JUnit, JBehave, we can really see how he applies this model right into the creation of tests. There are five steps: 1. Write story, 2. Map steps to Java, 3. Configure Stories, and 4. Run Stories. I have shown the second step below from his website just to show how well the stories map to the JBehave test harness.
JBehave even has a story editor in eclipse that will link to the corresponding JBehave Java method. Sometime soon I will give his system a go, simply because the concept plays so nicely with user stories. It really implies that each user story is a specific behavior, and that each behavior has a test associated with it. A lot of people might say that BDD is still TDD, but I think it is different in that it really forces you to abide by the practices created by agile development. For a novice agile developer, it makes the steps for utilizing user stories and TDD much more natural.
Sunday, December 2, 2012
Using __dict__ in Python and Private Attributes
In the last phase of the World Crises project, I was designed with creating the search functionality. Given the reasonable amount of data types in our Google app engine datastore, I soon tried to search out a way to iterate over the datastore without creating multiple loops with the same body. The problem is that these types are represented as fields of different app engine model objects. How would someone iterate over the instance fields of a class?
Well, the solution I came up with was to use the __dict__ variable in python. __dict__ is a "private" (Is anything really private in Python?) variable which contains the attributes in a class instance: all functions, variables, etc. Using this special field I am able to make a list of the model names I want to search, and then access them using the __dict__ dictionary.
Why does the variable start with two underscores? This is how private attributes are handled in Python. They aren't actually private, of course, because you can still access them, but they do lend themselves to be fairly awkward and ugly if you do try to use them. If you try to create attributes that start with two underscores, they will have their names mangled like so:
>>> class A:
... def __init__(self) :
... self.__x = 5
...
>>> A().__x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: A instance has no attribute '__x'
>>> A()._A__x
5
Well, the solution I came up with was to use the __dict__ variable in python. __dict__ is a "private" (Is anything really private in Python?) variable which contains the attributes in a class instance: all functions, variables, etc. Using this special field I am able to make a list of the model names I want to search, and then access them using the __dict__ dictionary.
Why does the variable start with two underscores? This is how private attributes are handled in Python. They aren't actually private, of course, because you can still access them, but they do lend themselves to be fairly awkward and ugly if you do try to use them. If you try to create attributes that start with two underscores, they will have their names mangled like so:
>>> class A:
... def __init__(self) :
... self.__x = 5
...
>>> A().__x
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: A instance has no attribute '__x'
>>> A()._A__x
5
As you can see, if you try and make a variable starting with two underscores yourself, Python will mangle it by prepending an underscore with the class name. Another interesting thing is that names starting with _ will not be imported with "from X import *".
The more you know...
Monday, November 19, 2012
Generating Search Results in Python
In the last phase of our project in CS 373, we are being asked to create a search feature in our website to search for data within the Google data store. Given that I have never done something like this before, a lot of questions arise: What tools and API's are already out there, so I don't reinvent the wheel? Should I retrieve single results at a time, or all of them at once? In our position, I believe the best way to do this is to do it ourselves.
When I took CS 307 my freshman year at UT, a guest speaker from Yahoo came and talked to us a little bit about generating search results and what they were doing to optimize their searches. The main optimization I remember was generating the results on a by-request basis. If the search page only asks for 10 results, only get the first 10 results. Since we are doing this project in Python, what better way than to do this with generators!
Really, the way we do our searches involves searching the data store for a certain query and yielding those results to the owner of the generator. It's perfect! If the search page wants 10 results, it can simply call .next() on the generator 10 times (assuming there are actually 10 results). If the user clicks 'next' on the web page, it can simply ask for another 10 as it pleases. For a project of our scale, it also allows us to prioritize our search by deciding which results get yielded first. For instance, if somebody searches "colorado", we would want the page for "Colorado Wildfires" to come up first, not where "colorado" simply comes up in the description of something else.
When I took CS 307 my freshman year at UT, a guest speaker from Yahoo came and talked to us a little bit about generating search results and what they were doing to optimize their searches. The main optimization I remember was generating the results on a by-request basis. If the search page only asks for 10 results, only get the first 10 results. Since we are doing this project in Python, what better way than to do this with generators!
Really, the way we do our searches involves searching the data store for a certain query and yielding those results to the owner of the generator. It's perfect! If the search page wants 10 results, it can simply call .next() on the generator 10 times (assuming there are actually 10 results). If the user clicks 'next' on the web page, it can simply ask for another 10 as it pleases. For a project of our scale, it also allows us to prioritize our search by deciding which results get yielded first. For instance, if somebody searches "colorado", we would want the page for "Colorado Wildfires" to come up first, not where "colorado" simply comes up in the description of something else.
Sunday, November 11, 2012
My New Perspective on Bug-Free Code
As some may know, I had the pleasure of spending Friday night and most of Saturday in the hospital. Disclaimer: I'm fine, just have a little something called Athletic Heart Syndrome and 8 stitches in my eye from fainting and introducing my face to the ground at Pho Saigon on North Lamar Friday night. Anyways, while the experience itself was pretty awful, my programming mind could not help but be in awe of the vast amounts of software around me that keep everything running smoothly.
The software on the electrocardiogram displays information about my heart and lets me and the staff know how many times my heart misses beats and stores this information the entire time I am there. Alarms are constantly being fired from different devices as the result of hardware communicating with software that something important has happened. It is imperative that the software running on these devices work absolutely as they are understood to. If somebody's heart stops and no one is alerted, I think we have a serious software issue! (Assuming the alarm happens at the software level)
I had the pleasure of having a sonogram, which is basically an ultrasound of the heart. Seriously, the software running on this machine was incredible. The nurse could click on different parts of my heart, and it would say how long each part of my heart was, it could differentiate between in and out flow color coded by red and blue. Of course the hardware is also very impressive, but being a programmer I can understand the amount of research and work that must have gone into designing that. If the software wrongly interpreted the data coming from the hardware, we could end up with false positives or negatives. I would imagine in a medical situation both of these are bad things. False positives mean that the patient could go home thinking he or she is fine when really that person has issues. False negatives mean that the patient could undergo expensive and possibly harmful treatment to a person that is actually o.k.
At the base of it, software in the medical world really has a low margin for error. How would you feel if a bug in software you wrote caused harm, even fatal harm, to another human being? Take a look at the Therac-25. It is a radiation therapy machine involved in at least 6 incidents between 1985-1987 because of a race condition with a byte counter that often overflowed. The other thing you might ask is: Is there really any code that isn't bug free? Well, when you write code, you introduce bugs. That's life, but we can minimize and reduce these bugs by following proper software engineering techniques and really believing in them. When you test, test as if someone's life depended on it. When you are getting ready to release software, ask yourself if someone's life were dependent on the software working correctly that they would be o.k. I would really like to see what kind of software engineering workflows are used in medical software and other life-dependent software such as aviation controls.
When you "buy into" some aspect of an engineering workflow like Test-Driven Development, treat it as if someone's life were dependent on it. That is what medical software engineers have to do, and I imagine it will make you a much more serious programmer if you treat it like they have to.
The software on the electrocardiogram displays information about my heart and lets me and the staff know how many times my heart misses beats and stores this information the entire time I am there. Alarms are constantly being fired from different devices as the result of hardware communicating with software that something important has happened. It is imperative that the software running on these devices work absolutely as they are understood to. If somebody's heart stops and no one is alerted, I think we have a serious software issue! (Assuming the alarm happens at the software level)
I had the pleasure of having a sonogram, which is basically an ultrasound of the heart. Seriously, the software running on this machine was incredible. The nurse could click on different parts of my heart, and it would say how long each part of my heart was, it could differentiate between in and out flow color coded by red and blue. Of course the hardware is also very impressive, but being a programmer I can understand the amount of research and work that must have gone into designing that. If the software wrongly interpreted the data coming from the hardware, we could end up with false positives or negatives. I would imagine in a medical situation both of these are bad things. False positives mean that the patient could go home thinking he or she is fine when really that person has issues. False negatives mean that the patient could undergo expensive and possibly harmful treatment to a person that is actually o.k.
At the base of it, software in the medical world really has a low margin for error. How would you feel if a bug in software you wrote caused harm, even fatal harm, to another human being? Take a look at the Therac-25. It is a radiation therapy machine involved in at least 6 incidents between 1985-1987 because of a race condition with a byte counter that often overflowed. The other thing you might ask is: Is there really any code that isn't bug free? Well, when you write code, you introduce bugs. That's life, but we can minimize and reduce these bugs by following proper software engineering techniques and really believing in them. When you test, test as if someone's life depended on it. When you are getting ready to release software, ask yourself if someone's life were dependent on the software working correctly that they would be o.k. I would really like to see what kind of software engineering workflows are used in medical software and other life-dependent software such as aviation controls.
When you "buy into" some aspect of an engineering workflow like Test-Driven Development, treat it as if someone's life were dependent on it. That is what medical software engineers have to do, and I imagine it will make you a much more serious programmer if you treat it like they have to.
Sunday, November 4, 2012
How to Study for Dr. Downing's Exams
Last week I learned a few valuable lessons, and for once I learned them in a good way. See, typically I do not do well on Dr. Downing's exams. They tend to feed off the things I almost know and should know, but just quite can't extract from the tip of my tongue. I always do well on the projects, go up and down with the quizzes, but the tests for me are always a wildcard. This one was different...
Friday, a networks project was due, and being that I was going mountain bike racing for the weekend come lunchtime Friday, I knew things were going to get a little hectic Wednesday and Thursday. During crunch time on Thursday afternoon, I think I found the best way to study Dr. Downing's test:
Fire up the Python interpreter and just start cranking examples.
Seriously. Go through all the slides. Define functions. Define new functions. Do them backwards. Now forwards. Upside-down. Do stupid examples, even things that you would normally think to be common sense because come test time, you very well might not know slight pythonic nuances simply because you've never dealt with them yourself. It's one thing to see things done for you in class, it's another thing to do them yourself. I'll say it again:
It's one thing to see things done for you in class, it's another thing to do them yourself.
Also, be a good boy and do the reading. Dr. Downing's readings are extremely helpful and respectably applicable to the real world. Not only will they help you become a more understanding programmer, but they most certainly will also score you a couple test answers.
This was probably the first test I've felt comfortable with, and it's simply from running through examples myself instead of just looking at them. Cheers!
Friday, a networks project was due, and being that I was going mountain bike racing for the weekend come lunchtime Friday, I knew things were going to get a little hectic Wednesday and Thursday. During crunch time on Thursday afternoon, I think I found the best way to study Dr. Downing's test:
Fire up the Python interpreter and just start cranking examples.
Seriously. Go through all the slides. Define functions. Define new functions. Do them backwards. Now forwards. Upside-down. Do stupid examples, even things that you would normally think to be common sense because come test time, you very well might not know slight pythonic nuances simply because you've never dealt with them yourself. It's one thing to see things done for you in class, it's another thing to do them yourself. I'll say it again:
It's one thing to see things done for you in class, it's another thing to do them yourself.
Also, be a good boy and do the reading. Dr. Downing's readings are extremely helpful and respectably applicable to the real world. Not only will they help you become a more understanding programmer, but they most certainly will also score you a couple test answers.
This was probably the first test I've felt comfortable with, and it's simply from running through examples myself instead of just looking at them. Cheers!
Sunday, October 28, 2012
Keyword Argument Unpacking in Python
Recently in Software Engineering we learned about "keyword argument unpacking" in Python. Many times when I learn weird language quirks and features like this, I often think about how the language feature can help the design of my program flow in a natural way; more natural than if the feature did not exist in the first place.
Keyword argument unpacking basically works by "decorating" the name of a dictionary with two prefixed asterisks in a function or method call which has argument keywords that have the same strings as the keys of the dictionary.
So basically, say we have the following function:
def f (x, y, z) :
return [x, y, z]
We can make the following call:
f(dict([(x, 1), (y, 2), (z, 4)])
Or the following call:
f(dict([(y, 2), (z, 4), (x, 1)])
Or in any other order and still got the same list back: [1, 2, 4]
Last wee this proved to be particularly useful in dealing with Google App Engine models mainly because the models can often be constructed with a subset of possible arguments. If you only want one call to the model constructor and the number of arguments is dynamic at runtime, then simply building a dictionary with the arguments and values of the call seems to be a very elegant solution. Before I thought to use it, I had a very ugly block with many if and else statements creating different models depending on which arguments to the model constructor were valid. Again, this way is much more elegant. It is limited, but I do believe I have found one of my new favorite features of Python.
Keyword argument unpacking basically works by "decorating" the name of a dictionary with two prefixed asterisks in a function or method call which has argument keywords that have the same strings as the keys of the dictionary.
So basically, say we have the following function:
def f (x, y, z) :
return [x, y, z]
We can make the following call:
f(dict([(x, 1), (y, 2), (z, 4)])
Or the following call:
f(dict([(y, 2), (z, 4), (x, 1)])
Or in any other order and still got the same list back: [1, 2, 4]
Last wee this proved to be particularly useful in dealing with Google App Engine models mainly because the models can often be constructed with a subset of possible arguments. If you only want one call to the model constructor and the number of arguments is dynamic at runtime, then simply building a dictionary with the arguments and values of the call seems to be a very elegant solution. Before I thought to use it, I had a very ugly block with many if and else statements creating different models depending on which arguments to the model constructor were valid. Again, this way is much more elegant. It is limited, but I do believe I have found one of my new favorite features of Python.
Subscribe to:
Posts (Atom)